






-
语音打断功能:深入语音识别技术 设计语音用户界面
adinnet / 2018-04-09 16:21 /UI界面设计

语音打断功能常用于交互式语音应答(IVR)系统,从而用户可以随时中断系统。当系统检测到任意语音时,它都会立即停止播放当前的提示并开始收听用户说话,如下面的示例所示。

在IVR 领域,语音打断功能的好处显而易见。IVR 系统的菜单或选项列表一般都很长,而且流程烦琐,总是强迫用户等待。对于经常使用IVR 系统的用户而言尤其如此。
当你允许用户打断系统时,你在设置提示和问题间的停顿时需格外小心。下面是一些可能出错的例子。(语音用户界面,VUI)

在上面的示例中,系统在第一个问题之后有个短暂停顿。这时候,用户开始说话。但就在此时,系统还在继续说它的指令。于是,用户觉得自己打断了系统说话,于是停止说话,但为时已晚:系统此时也停止了说话。
对话就这样中断了,而且可能还需要一个错误提示,来让用户重新回到对话中。想象一下,在手机信号不好的情况下与某人交谈——可能会有明显的通话滞后,而通话双方经常互相掩盖对方的声音。
这个对话示例还有另一个问题。当系统问用户一个问题时,用户很自然地回答了。设计时应避免在提问之后还附带很多额外的信息,因为用户往往会抢在你的提示语音结束之前,直接回答问题。
更好先列出用户能做的事情,然后再问问题。

当系统正在执行一个需要很长时间的操作或者朗读大量信息时,打断功能也非常有用。例如,当Amazon Echo 播放一首歌曲时,你可以随时打断说:“Alexa,停止播放。”如果没有打断功能,用户就没法用语音指令来停止音乐播放。
然而,与传统的IVR 系统不同是,Alexa 并不是检测到任何语音都会停止说话——只有听到唤醒词时才会停止。有时我们也称之为“热词”(hot word)或“魔法词”(magic word)。这是一种非常巧妙的做法,除非系统识别到特定的关键字或短语,否则它不会停止执行/说话。这种处理方式在某些情况下非常有效。试想一下,你让Alexa 播放某个电台。然后,你开始和你的家人聊天。如果此时Alexa 因为听到你说话就对你说:“对不起,你说什么?”这将是多么糟糕的用户体验。相对的,忽略用户说的话,直到识别到唤醒词,这样的用户体验就会好很多。
热词在IVR 领域中也曾被使用,但只限于特定场景下。例如在旧金山湾区511 IVR 系统中,用户可以通过电话获取交通信息、预估行驶时间,或者进行其他操作。在用户提供了高速公路名后,系统会寻找相关的交通事故并把这些信息一条条念给呼叫者听。当时,我希望用户能灵活地跳过其中某一条信息直接听下条信息,但又担心汽车里的背景噪音或其他输入内容会使系统中断。
试想一下,你正在收听10 起交通事故的信息,你打个喷嚏结果系统停了下来,跟你说:“对不起,我没听到你说什么。”于是你又要从头开始听!
而使用热词技术之后,系统只会在播报信息时识别少数几个关键词,例如“下一条”和“上一条”。当用户说话时,系统不会像一般的打断模式一样立刻停止播报。除非系统识别到了某个关键字,此时它才会停止播报并进行下一步操作。
另一个使用热词的场景是,用户需要在对话中先暂停并完成一项操作。这种一般发生在用户需要去找一些物品来回答问题的时候,比如在续订处方的过程中,用户需要去拿一个药瓶来确认处方编号。此时系统问:“你需要一些时间来确认处方编号吗?”如果用户说“是的”,系统会提示用户在找到后说句“我回来了”或者“继续”。这也就相当于暂停了对话。
对于那些不仅仅依赖于语音的VUI 系统,不建议经常使用打断功能。比如,如果你的VUI 使用了预先录制的视频,就不应该使用打断功能。因为被打断时,预先录制的视频很难处理。难道视频应该突然停止吗?之后要从刚才停止的地方重新开始播放吗?
当你的VUI 系统有一个虚拟形象或者预先录制的视频时,它的体验会更像和一个真人进行交谈,用户往往会更有礼貌,并耐心等待系统把话说完。当虚拟形象或预录视频说话时,用户可能也在说话(与别人交谈),显然此时用户并不需要虚拟形象听自己说话。
如果你的系统没有启用打断功能,请不要强制用户收听很长的列表或菜单,而应该把事情分成更多的步骤,并依靠可视化的列表来减轻认知负担。例如,如果用户必须从7 个视频中进行选择,千万别让系统一条一条读出来。你可以使用可视化的信息呈现方式,如图所示。
你可以试想一下手机逐条读出所有标题的情景。显然用可视化的方式来显示这些标题会更自然,除非用户不能看屏幕(比如用户视力受损)。
有关语音打断功能的更后一点说明是,一些ASR 工具可以调整语音打断功能的敏感度。你可以升高或者降低它的敏感度(越不敏感,用户想打断系统就越困难)。
1.超时
VUI 系统除了要注意用户什么时候说话,还要知道用户什么时候停止说话。能够检测到用户什么时候问完了问题,或是什么时候答完了系统的提问,对于优秀的VUI 体验而言是必不可少的。如果做不到这些,用户就无法确定系统是否已经听到了自己说的话。
用户不仅会对系统失去信心,用户与系统的对话也会因为陷入一次又一次尴尬的开始和停顿而无法继续。你有没有在视频聊天过程中遇到过轻微的延迟现象?这看起来是件小事,但是当你不知道别人是否说完的时候,谈话会变得艰难又痛苦。
2.语音终止超时
对于优秀的VUI体验来说,更重要的就是要做好语音端点检测。这意味着,系统知道用户什么时候说完了(换而言之,用户在对话中完成了话轮)。
一些语音识别引擎允许你通过设置语音终止超时时间来配置语音端点检测功能。语音终止超时时间是指在系统判定用户说完之前,用户说话时可暂停的时间长度。
并不是所有语音识别引擎都允许你自己来设置超时时间,但你至少需要知道默认值是多少。从经验来看,1.5 秒的时间长度适用于大多数类型的VUI 系统。如果时间太短,你会在用户结束说话之前打断用户;如果时间太长,用户就会怀疑系统是否听到了他们说的话。
如果可以设置,那么在某些场景下你可以调整超时时间。一个设计巧妙的VUI 系统需要有足够的灵活性,并在不同的情景下设置不同的超时时长。例如,当用户启动系统时(比如说:“OKGoogle”,或者按苹果Home 键激活Siri)比用户回答“你今天好吗?”时所需的超时时长更短。在前面一种情况下,因为是用户主动触发了事件,所以通常用户不需要停顿很久,就知道自己要些说什么。而在后面那种情况下,用户可能会先停顿一下,然后一点点开始说,比如,“我感觉……嗯,早些时候我还好好的,但现在我……我有点头疼。”这种时候,如果超时时间设置得太短,系统会在用户在说完之前就打断用户,这在对话中是非常粗鲁的行为。
另一个常见的情况也需要较长的语音终止超时时间:当人们读分组的数字(如信用卡卡号)时,人们自然而然地会在数字分组之间停顿,而这时候你不应该打断用户。
分析数据是了解如何调整语音终止超时时间的更佳方法。通过查看真实用户所说的录音文本,你可以找到用户说话时经常暂停的地方。而你需要在这些地方增加语音终止超时时长。
在对话中,当你预计用户会说很多话时,或者觉得用户可能会犹豫时,你就可以适当延长超时时间。例如,当一个保险App 让用户复述车祸发生的细节时,用户可能会说多个句子,而且会在梳理表达时偶尔停顿一下。
而在一些特定场景下,你还可以缩短语音终止超时时间。比如当用户只需要回答“是”或“否”时,较短的超时时长可以让对话更流畅高效。
3.无语音超时
另一种重要的超时用于未检测到语音(NSP)的情况。无语音超时和语音终止超时需分别处理,因为:
NSP 超时时间比语音终止超时时间更长(通常为10 秒左右)。
针对NSP 超时,VUI 系统会执行不同的操作。
无语音超时能帮助系统分析哪里存在问题。
在IVR 系统中,当语音识别引擎开始接收用户回复并且在一定时间内没有检测到任何语音时,就会触发NSP 超时。然后,由VUI设计师决定在这种情况下系统应该做什么。在IVR 系统中,此时系统通常会给用户一条错误消息,例如“对不起,我没有听到。你在哪天旅行?”并等待用户发言。
有时候系统在NSP 超时触发后不会执行任何操作。例如,如果你说“Alexa”并激活了Amazon Echo,然后你不说话,大约8 秒后Echo 设备顶端的蓝色指示灯将熄灭,Alexa 也会保持沉默。
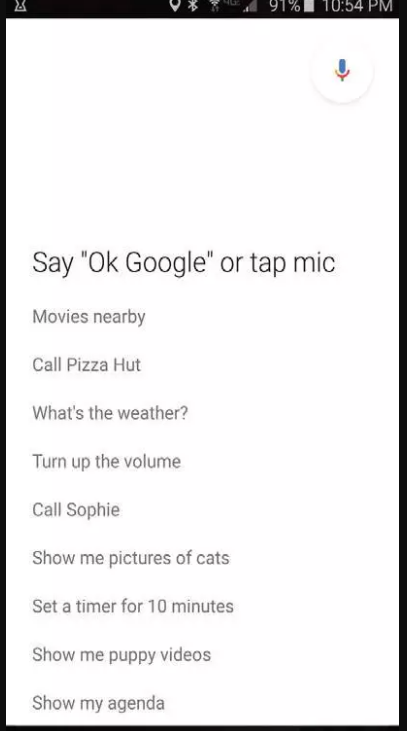
如果你不说话,OK Google(见图2)会等待大约5 秒,然后它会在屏幕上弹出一个提示,其中列举了一些你可以说的话,例如“叫一份比萨饼”和“给我看一些猫的图片” (网络中更常见的用途)。Siri 和Cortana 在超时之后也会展示一些示例(见图3 和图4)。
有时候什么都不做也是一种合理的设计。在这些情况下,用户很清楚系统没有听到他们说话,通常也会再次尝试。



在上述案例中,系统没有明确提示用户NSP 超时。这些案例也展示了如今常见VUI 系统的不同模式。如今许多虚拟助理仍处于“一次性”(one-off)的模式:它们等待用户说话并对此做出回复,然后通常对话就这样结束了,直到用户开始一个新的请求。在IVR系统中,用户处于必须输入语音否则无法继续的对话之中,这时提示用户NSP 超时就很合理了。
还有一种情况,即当你使用一个视频或虚拟形象时,系统在NSP 触发时更好什么都不要做。如果系统没有听到用户的声音,就继续等待,看着就像在等用户说话的样子就好,而这也是人类对话中,你对一个人说话而那人却听不到你的声音时出现的一种常见暗示。
当用户受阻时,你需要为NSP 事件设计更多的内容。比如当用户在一个有虚拟形象的对话式系统中,触发了多个NSP 超时,你需要给用户一个退出系统的方式。如果系统有基于屏幕的图形用户界面(GUI),展示一个按钮就足以帮助用户退出系统。
GUI 可以一直等待,直到用户执行了操作——比如网站就不会存在超时问题(除非你要抢音乐会门票)。
但在一个完全基于语音的系统中,你可以采用“即时”帮助。有一个来自Volio 创建的iPad 应用程序的例子,它使用了预录的视频(http://bit.ly/2hcpvv4/)。该App 模拟了用户与《Esquire 杂志》的专栏作家Rodney Cutler 的对话,提供了关于护发产品的建议。
在交谈中,用户的头像会显示在右上角的画中画里。当轮到用户说话的时候,他们的头像边框会变为绿色。
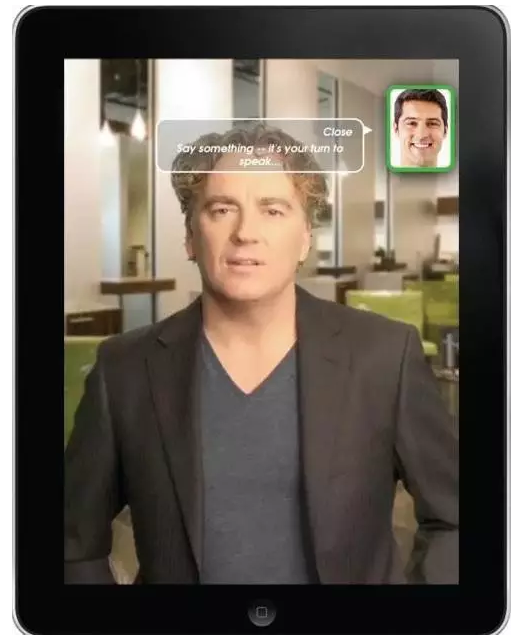
如果系统未检测到任何语音,就不会执行任何操作——演员继续保持“倾听”的状态,偶尔会点头并看着用户。
如果系统检测到多个NSP 超时,App 就会弹出一个提示:“现在轮到你说话了,说吧。”
在另一段与《Esquire 杂志》的对话中,用户与专栏作家NickSullivan 讨论在约会时要穿什么。这个例子为大家展示了在多次误识别或触发多次NSP 超时之后,App 可以做出什么反馈。首先,右上角的图标缓慢地闪烁。当用户点击它时,会出现一个带选项的下拉菜单,让用户通过触摸选择对应的答复以继续对话。用户选择后,菜单消失。
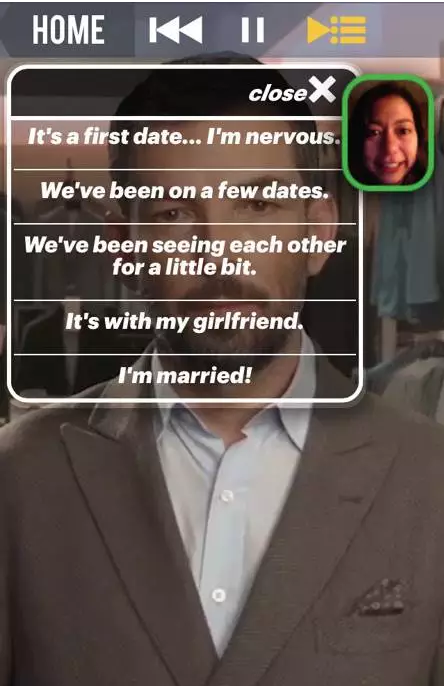
在你设计系统时,你需要花一些时间来思考为什么会触发NSP 超时。首先,尽管系统觉得它没有听到任何对话,但这有可能是误判。
还有一种可能,就是用户确实说话了,但语音识别引擎没有接收到声音。
一些设计师会给出一些提示,比如说“请大声点”或“请靠近麦克风”。但这些提示可能并不能解决用户的问题:如果是因为用户声音太小导致系统未接受到声音,提示用户说大声点只会让用户重复强调个别词语,而这往往不能解决语音识别的问题。相对的,设计应该围绕如何让用户进入下一步来进行。通常,你可以让用户重复之前的行为,或者在多次NSP 超时之后,提供一种替代的方式来让用户输入信息。
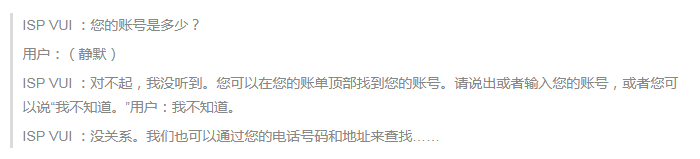
当然,有时候用户真的什么也没说。作为一个设计师,请思考一下为什么用户什么也没说?如果数据显示,在你的App 流程中有一个特定的地方用户常常不说话,请细地检查交互流程。下面的例子中,用户通过App 支付网络服务提供商(ISP)账单,这其中就有一个问题导致了频繁的NSP 超时。案例向我们演示了一种糟糕的处理方式。

正如你想的那样,到更后系统也没能成功。这是因为用户没有得到帮助。而系统只是不停地重复同一个问题。
你认为是什么导致这个问题触发了多次NSP 超时?试想你的用户正打算缴费,但他们不知道需缴费的账号。这时候他们能做什么?
下面是一个能让对话继续下去的示例。
第二个例子的做法好在哪里呢?首先,如果用户有账单,系统会告诉用户哪里可以找到他们的账号。其次,如果用户不知道或找不到他们的账号,系统能让对话通过另一种方式继续进行下去。
4.言语过多
另一种超时( 较少出现) 是言语过多(Too-Much-Speech,TMS)。这种超时会在用户说话时间过长,且没有能触发语音终止超时的停顿时出现。对于大多数系统来说,通常不需要处理这种情况,因为用户总需要在某个时候喘口气。但更好还是在部署的应用程序时监视这个事件,因为它可能表示语音识别引擎触发了某些非典型语音,你需要确定具体原因。
但是,如果你发现自己设计的系统会促使用户说很长的语段,并且用户的发言经常过长,你就可以设置TMS 超时来打断用户以便继续进行对话。更好能根据现有数据来确定你的TMS 超时时间,当然你也可以先设置一个比较长时间的TMS 超时(否则会太轻易地打断用户),例如7 ~ 10 秒。
本文标签:
语音用户界面设计


 沪公网安备 31011502005248
沪公网安备 31011502005248

 咨询热线:400-021-8655
咨询热线:400-021-8655 微信联系:17702199087
微信联系:17702199087